


금일 포스팅에선 Spark의 몇가지 조인 전략에 대해 어떤 상황에서 사용하면 좋은지 실습을 하며 확인한 과정을 공유하고자 한다.
사용한 실습 코드들은 다음 레포에 존재한다.
https://github.com/Choiwonwong/local-spark
GitHub - Choiwonwong/local-spark: spark practice in local
spark practice in local. Contribute to Choiwonwong/local-spark development by creating an account on GitHub.
github.com
우선, 조인 실습은 테스트 셋을 통해 진행했는데, 레포 내의 join_test/data_gen.py 스크립트를 실행하여 간단히 생성할 수 있다.
해당 스크립트를 통해, 4가지 데이터 셋을 만들게 된다.
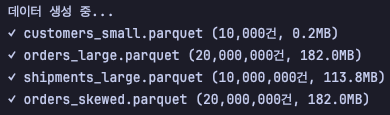
- customers_small.parquet : 10,000건, 약 0.2MB
- orders_large.parquet : 20,000,000건, 약 180MB
- shipments_large.parquet : 10,000,000건, 약 100MB
orders_skewed.parquet : 20,000,000건, 약 180MB- skew 상황을 만들어보려 했는데 실패했다.
DW에 저장된 데이터로 가정하여, parquet 포맷을 사용했다.
위 데이터 셋으로 아래 3가지 상황을 가정한다.
- 작은 데이터셋과 큰 데이터셋의 조인 및 집계
- 큰 데이터셋 간의 조인 및 집계
작은 데이터셋과 데이터가 쏠려 있는(Skew) 큰 데이터셋의 조인 및 집계 (1%의 customer가 95%의 주문을 차지)
로컬 환경은 다음과 같다.
- MacOS 14Core (10P+4E), 36GB Memory
- uv, python 3.10, pyspark 3.5.6
Case1 - 작은 테이블 + 큰 테이블 조인
사용 데이터 : customers_small, orders_large
고객 데이터와 주문 데이터를 결합해서 고객별 주문 양을 계산하는 시나리오와 고객 데이터의 양이 주문 데이터와 비교했을 때, 많이 작은 상황을 가정했다.
우선 가장 간단하게 다음과 같이 조인, 집계를 수행하고, spark 옵션은 디폴트로만 사용했을 때 결과는 다음과 같았다.
summary_with_inner = orders_df.join(customers_df, "customer_id", "inner").groupBy("customer_name") \
.agg(count("order_id").alias("order_count"),
spark_sum("amount").alias("total_amount"))
Inner Join을 통해 orders <- customers를 결합하고 , customer_name으로 그룹화한 후 order의 개수와 양을 집계했다.
이 과정에 약 1.24s가 소요되었다.
Driver UI로 실행 결과를 확인해보면, 다음과 같이 10,000건의 customer 데이터가 BroadcastHashJoin을 통해 20,000,000개의 데이터와 결합하게된다.

이 과정에서 별도의 셔플이 발생하지 않는 것을 확인할 수 있었다. 즉, spark가 알아서 작은 데이터셋을 확인 한 후 Broadcast Hash Join 전략을 사용해 조인을 수행했다.
customers_df와 orders_df 순서를 변경해도 BroadcastHashJoin으로 동작하게 된다.
추가적으로 기본 조인 전략인 SortMerge Join을 수행하면 어느정도 소요되는지 확인하기 위해서 다음 옵션을 설정하였다.
builder.config("spark.sql.autoBroadcastJoinThreshold", "-1")
결과는 정상적으로 나왔고 소요 시간은 약 3s 정도로 앞선 방식보다 2배 이상 소요되었다.
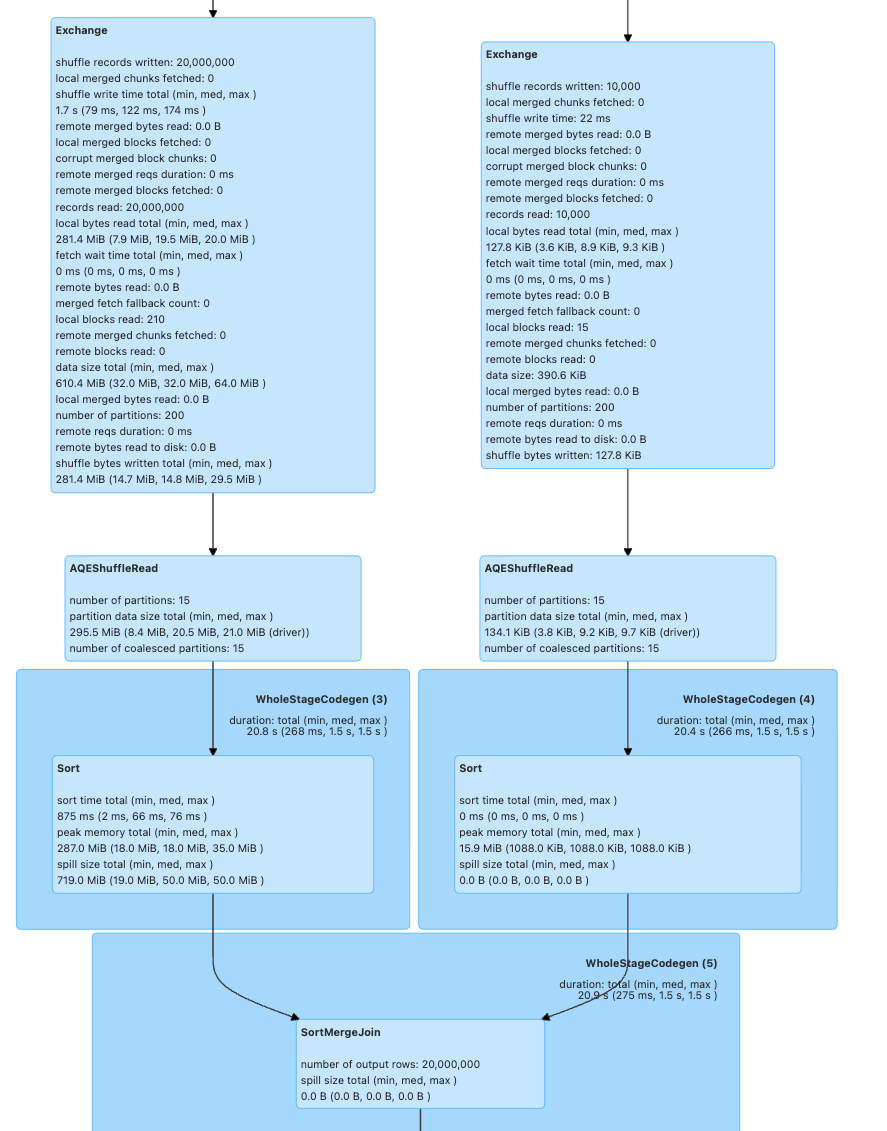
Driver UI를 확인해보면, 앞선 DAG와 다르게 SortMergeJoin을 통해 두 데이터셋의 결합이 진행되었다.
이 과정에서 280MB, 128KB의 셔플링이 발생하였다.

추가적으로, Inner Join을 Left Join으로 변경하고, customer <- order로 조인을 변경하면 브로드캐스팅이 일어나는지 확인했을 때는, 브로드캐스팅 대신 SortMergeJoin을 사용하게 된다.
summary_with_left = customers_df.join(orders_df, "customer_id", "left").groupBy("customer_name") \
.agg(count("order_id").alias("order_count"),
spark_sum("amount").alias("total_amount"))
구조적 API를 사용할 때 BroadcastHashJoin 명시하기 위해선, sql.functions.broadcast 함수를 사용할 수 있다.
다만, 위 코드를 broadcast(customer_df).join(orders_df) 방식으로 변경하고 실행해보면 다음과 같은 경고를 확인할 수 있고, BroadcastHashJoin으로 수행되지 않는 것을 확인할 수 있었다.

하나 확인해본 사항은 다음과 같이 orders_df에 broadcast를 걸어도 BroadcastHashJoin을 수행하는지를 확인해보았다.
summary_with_left = customers_df.join(broadcast(orders_df), "customer_id", "left").groupBy("customer_name") \
.agg(count("order_id").alias("order_count"),
spark_sum("amount").alias("total_amount"))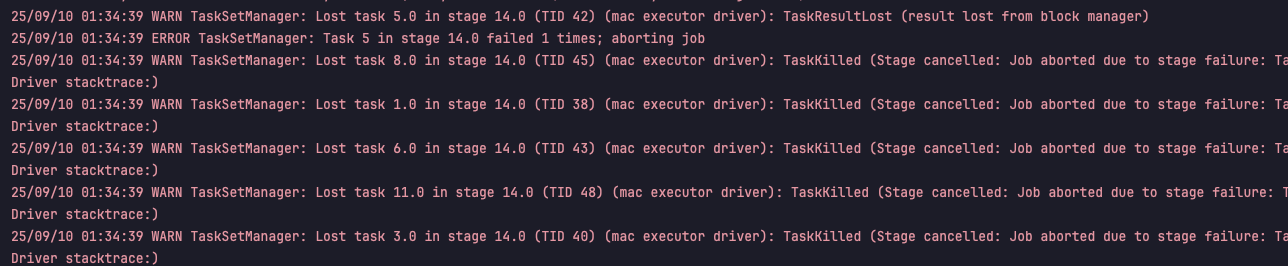
기본 설정으론 Task바로 실패하는 것을 확인할 수 있었고, JVM Heap OOM이 발생하였다.

이를 정상적으로 실행해보기 위해 Drivier 메모리를 3GB로 올려보고 진행해보면, BroadcastHashJoin이 처음과 정 반대로 걸린 것을 확인할 수 있다.
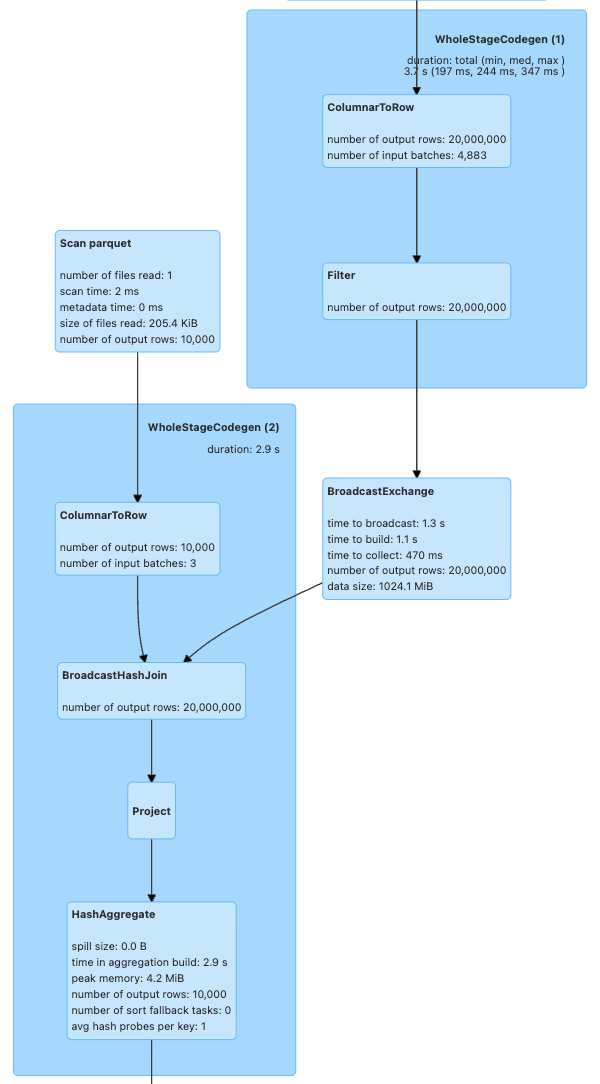
20,000,000의 데이터를 넘겨주는 과정에서 약 1GB의 메모리가 사용되었고, 기본 메모리 설정에서 OOM이 발생하였다.
결론
작은 데이터와 큰 데이터의 조인에서는 다음과 같은 특징을 확인할 수 있었다.
- Spark는 기본적으로 작은 테이블을 자동 감지해 BroadcastHashJoin을 선택한다. 이때 셔플 없이 빠른 성능(1.24s)을 보여준다.
- 강제로 SortMergeJoin을 사용하면 약 2배 이상의 시간(3s)이 소요되고 셔플이 발생한다.
- 따라서, 작은 테이블+큰 테이블 상황에서는 브로드캐스트가 명백히 유리하다.
- 조인 타입(Inner vs Left)과 순서에 따라 최적화 전략이 달라질 수 있다. Left Join에서는 브로드캐스트가 제한적으로 적용된다.
- broadcast() 힌트 사용 시 메모리 용량을 충분히 고려해야 한다. 큰 테이블을 브로드캐스트하려면 Driver 메모리가 충분해야 하며, 그렇지 않으면 OOM이 발생한다.
Case2 - 큰 테이블 간 조인
사용 데이터 : orders_large, shipments_large
order_id를 기준으로 조인하여 배송 상태별 주문 개수와 배송 비 평균을 집계하는 시나리오를 가정했다.
이 케이스에서는 두 테이블의 데이터 볼륨은 각각 180MB, 110MB 정도로 앞선 시나리오와는 다르게 데이터 셋의 크기가 비슷하다.
해당 조인과 집계는 다음과 같이 수행하였다.
joined_result = orders_df.alias("o").join(
shipments_df.alias("s"),
"order_id",
"inner"
)
status_summary = joined_result.groupBy("s.status") \
.agg(count("order_id").alias("order_count"),
spark_sum("o.amount").alias("total_amount"),
avg("s.shipping_cost").alias("avg_shipping_cost"))
10,000,000 & 20,000,000의 데이터셋을 조인하고 집계하는데 대략 13s가 소요되었다.
Driver UI를 확인해보면, 정확하게 sortMergeJoin을 사용하였고, 데이터들의 셔플이 일어나는 것을 확인할 수 있다.


Shuffle Write & Read 수치를 확인하면, 약 1GB의 Shuffle Write과, 587MB의 Shuffle Read가 발생했다.
결론
큰 데이터 간의 조인에는 다음과 같은 특징을 확인할 수 있었다.
- 양쪽 테이블 모두 브로드캐스트 임계값(10MB)을 초과하면 SortMergeJoin이 선택된다.
- SortMergeJoin에서는 양쪽 테이블 모두 셔플이 발생한다.
- Case1(1.24s) 대비 약 10배 이상의 시간(13s)이 소요되었다. 네트워크 셔플과 정렬 오버헤드로 인한 성능 차이가 명확히 드러난다.
- 메모리 사용량도 크게 증가했다. 정렬 과정에서 각각 1.4GB, 1GB의 메모리를 사용했다.
Case3 - 스큐 데이터와의 조인
사용 데이터 : customers_small, orders_skewed
임시적으로 스큐 상황을 만들어보기 위해 여러번의 시도를 진행했지만, 테스트 셋에서 명확한 스큐 상황을 만들진 못하였다. (나중에 다시 도전)
이론적인 측면에서 스큐 상황일 때 풀어갈 수 있는 방안을 확인했을 때 다음과 같다.
- AQE (Adaptive Query Execution) 스큐 조인 관련 옵션을 활성화한다.
- 런타임에 각 파티션 크기 측정하여 임계치를 초과하면 스큐로 판단하고, 해당 파티션을 여러 개로 분할하여 병렬 처리한다.
- BroadcastHashJoin 강제 적용
- 셔플 자체를 회피하여 스큐 문제를 차단할 수 있다.
- 다만, 테이블 크기 제한이 존재하여 사용할 수 없는 상황이 존재한다.
- 양쪽 테이블 모두 조인 키에 Salting을 적용하여 스큐된 키를 여러 파티션에 분산한다.
- 스큐가 예상되는 조인 키에 _0, _1 ~ 등으로 분산하여 실제 여러개의 값으로 분할하는 방식
- 모두 해당 로직 적용이 필요
- 사전 집계 & repartition
- 사전에 집계를 별도로 수행한 후 스큐된 데이터와 결합하는 방법 -> 사전 집계
- 임시적인 방안으로 repartition을 수행하여 파티션 내의 데이터를 균등하게 분할
정리
Spark 조인 전략별 특징은 다음과 같다.
BroadcastHashJoin
가장 빠른 조인 전략으로, 작은 테이블을 모든 executor에 복사해서 네트워크 셔플 없이 조인을 수행한다. Spark가 다음 조건을 만족할 때 자동으로 선택한다.
- 한쪽 테이블의 크기가 spark.sql.autoBroadcastJoinThreshold 이하일 때 (기본값 10MB)
- 조인 타입이 Inner, Left (Outer), Left Semi, Left Anti, Right Outer 등
- Left, Left Semi, Left Anti, 조인의 경우 오른쪽 테이블만 브로드캐스트할 수 있다.
- Right Outer의 경우 왼쪽 테이블에서 가능하다.
동작 방식
- 작은 테이블을 Driver에서 로드한 후 모든 executor에 브로드캐스트한다.
- 각 executor는 자신이 담당하는 큰 테이블의 파티션과 브로드캐스트된 작은 테이블을 로컬에서 해시 조인한다.
- 이 과정에서 큰 테이블은 전혀 이동하지 않아 네트워크 비용이 최소화된다.
강제 적용 방법
result = large_df.join(broadcast(small_df), "key")
이 경우 10MB 제한을 무시하고 강제로 브로드캐스트하지만, Driver 메모리가 충분해야 한다.
SortMergeJoin
Spark의 기본 조인 전략으로, 양쪽 테이블 모두 브로드캐스트할 수 없을 때 사용되는 안정적인 조인 방식이다. 양쪽 테이블을 조인 키로 정렬한 후 순차적으로 병합하여 조인을 수행한다.
- 양쪽 테이블 모두 spark.sql.autoBroadcastJoinThreshold를 초과할 때 (기본값 10MB)
- 등가 조인(equi-join)인 경우
동작 방식
- 양쪽 테이블을 조인 키의 해시값으로 파티셔닝해서 동일한 키를 가진 데이터들이 같은 파티션에 모이도록 셔플한다.
- 각 파티션에서는 조인 키로 데이터를 정렬한 후, 정렬된 두 데이터셋을 순차적으로 스캔하면서 병합한다.
- 이 과정에서 양쪽 테이블 모두 네트워크 셔플이 발생한다.
ShuffleHashJoin
SortMergeJoin이 '정렬'을 사용하는 반면, '해시 테이블'을 사용한 조인 방식이다.
즉, 셔플을 수행하여 파티션 내에 같은 키끼리 모이게 한 다음, 정렬이 아닌 해시 테이블을 통해 조인을 수행한다.
동작 방식
- 양쪽 테이블을 조인 키의 해시값으로 파티셔닝해서 동일한 키를 가진 데이터들이 같은 파티션에 모이도록 셔플(SortMerge와 동일)
- 각 파티션에서는 작은 쪽 테이블로 해시 테이블을 메모리에 구성하고, 큰 쪽 테이블을 스트리밍하면서 해시 룩업을 통해 조인.
- 정렬 과정이 없어 SortMergeJoin 보다는 빠르지만, 메모리 요구량이 높다.
메모리 옵션 조절이 필요한 전략이다.
Skew Join
조인 전략은 아니지만 같이 묶어 정리하면, 데이터 분포가 불균등하여 특정 파티션 혹은 조인 키에 데이터가 집중되어 있는 상황을 의미한다.
일부 파티션에만 작업이 일어나고, 나머지 파티션들은 대기하게 되어 전체 작업이 지연되는 상황이 발생한다. 최악의 경우에는 하나의 Task에서 OOM 으로 실패하게 된다.
발생 조건
- 조인 키의 분포가 많이 불균등할 때
- 날짜별 조인에서 특정 날짜에 데이터가 몰릴 때
해결 방법
- AQE 옵션 활용 : 런타임에 파티션 크기를 측정해서 임계값을 초과하는 스큐 파티션을 자동으로 여러 개로 분할
- Salting 기법 적용 : 수동으로 스큐를 해결하는 방법. 조인 키에 랜덤 값을 붙여서 하나의 스큐된 키를 여러 개의 키로 분산
- 사전 집계 : 조인 전에 스큐된 테이블을 미리 집계해서 데이터 크기를 줄이는 방법
- BroadcastHashJoin 활용 : 가능하다면 스큐 상황을 원천적으로 우회할 수 있는 방안
Reference
https://spark.apache.org/docs/latest/sql-performance-tuning.html#optimizing-the-join-strategy
Performance Tuning - Spark 4.0.1 Documentation
spark.apache.org
Performance Tuning - Spark 4.0.1 Documentation
spark.apache.org
https://spark.apache.org/docs/latest/sql-performance-tuning.html#optimizing-skew-join
Performance Tuning - Spark 4.0.1 Documentation
spark.apache.org
'Tech > Data Engineering' 카테고리의 다른 글
| 로컬에서 스트리밍 파이프라인 올려보기 with AI (1) | 2025.08.31 |
|---|---|
| Spark BufferHolder 메모리 한계 해결하기 - explode -> RDD Flatmap, 제너레이터 (3) | 2025.08.19 |
| Hive Json Serde의 한계 - Parquet/ORC 포맷 (2) | 2025.08.18 |
| Redis를 활용한 데이터 수집 프로세스 병렬 처리 및 안정성 확보 (5) | 2025.08.17 |
| Hive Table 복구 회고 with Airflow catchup 설정 (0) | 2024.07.27 |