


한달 전에 초안을 작성했는데, 블로그에 신경을 잘 못쓰느라 이제서야 마무리하고자 한다.
# 진행된 요소
일회성으로 제목, 링크, 가격, 배송비, 등록일, 카테고리, 광고유무, 판매자 정보를 한 페이지 크롤링 후 엑셀 파일로 저장
네이버 쇼핑 확장성 있게 크롤링하기 with Selenuim & Excel - 1
# 목적 네이버 쇼핑 사이트의 제품명, 가격 등에 대한 데이터들을 확장성을 갖고 정기적으로 수집이 가능한 Python 실행 프로그램을 구현하기 위함이다. 직접 requests을 사용해 파싱할 HTML 문서를
alive-wong.tistory.com
# 진행할 요소
- N개의 쿼리명이 저장된 엑셀 파일을 읽어 해당 쿼리에 대한 크롤링 결과물을 반환
- 충돌이 일어나지 않도록 결과 파일을 저장
- 쿼리와 함께 크롤링할 페이지 개수를 받아 쿼리별 N개의 페이지까지 크롤링을 수행
- 쿼리 파일 명을 Argument로 받도록 인터페이스를 제작
# 별도의 엑셀 파일에서 쿼리 및 페이지 개수 받아오기
우선, 별도의 엑셀파일에 쿼리와 쿼리별 페이지 수를 저장하고 Python에서 이를 읽도록 만든다.
쿼리 파일 명은 Argument로 받아 동작하도록 인터페이스를 구축하고, 한 페이지를 크롤링하는 기존 코드에 통합한다.

위와 같이 A 열에는 쿼리를 담고, B 열에는 탐색할 페이지 수를 지정한 파일을 사전에 정의했다

위 방식으로 test.xlsx 파일을 읽어 쿼리와 페이지 개수를 받아올 수 있다. 쿼리 파일의 Path는 queries로 고정시켰다.
이후, Argument를 사용하여 쿼리 파일명을 지정할 수 있도록 인터페이스를 구현했다.
from openpyxl import load_workbook
import sys
if sys.argv[-1] == sys.argv[0]:
print("쿼리 시트가 입력되지 않았습니다.")
print("사용 방법은 main.py [쿼리 시트 명]입니다. 다시 시도해주세요")
elif len(sys.argv) >= 3:
print("쿼리 시트 지정이 정확하지 않습니다.")
print("입력된 매개 변수의 수가", len(sys.argv) - 1, "개입니다.")
print("쿼리 시트 지정을 하나로 지정해주세요.")
else:
fileName = sys.argv[1]
queryPath = "queries/" + fileName + '.xlsx'
queries = load_workbook(queryPath, data_only=True)
queriesSheet = queries['시트1']
queriesSheet.delete_rows(0)
for index, row in enumerate(queriesSheet.rows):
if index == 0:
continue
print(row[0].value, row[1].value)
시트 명 입력 부분의 간단한 예외 처리를 추가하여 인터페이스를 지정하였다.
이후 기존 크롤링 코드에 해당 부분을 통합하여, 아래와 같이 동작되도록 프로그램을 작성했다.
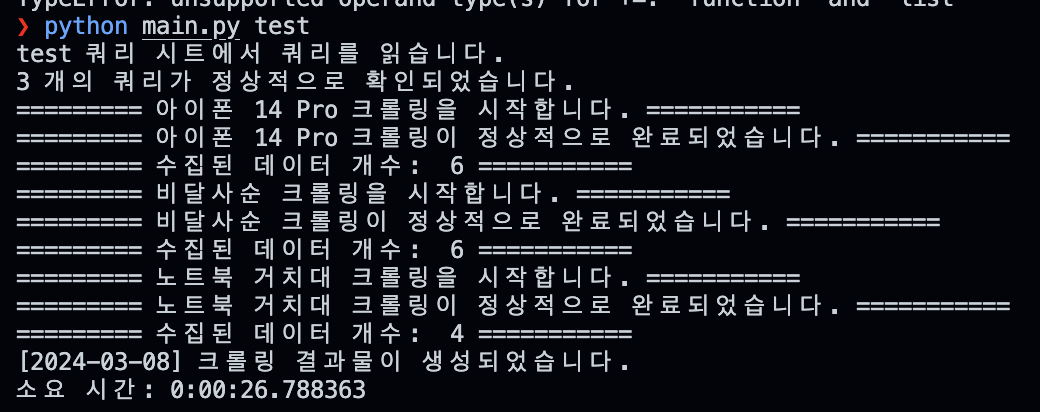
현재 단계의 프로그램 실행 결과이다. test.xlsx에 저장된 쿼리에 맞게 크롤링을 수행하고 수집된 데이터를 가져온다.
추가적으로 진척도를 확인하기 위한 메시지를 출력했다.
현재 테스트를 위해서 광고 제품만을 크롤링하고 있는데, 결과물도 정상적으로 반환된다.

# 페이지 전환
위 코드에서 페이지를 전환하는 로직을 추가해야했다.
쿼리 파일에 명시되어 있는 개수만큼 for문을 통해 네이버 쇼핑 탭의 "다음"을 눌러 페이지 전환을 수행했다.
일반적으로 페이지 전환은 URL의 Page 부분을 수정하여 구현하지만, 이번 프로그램에서는 해당 방식은 지양해다.

네이버 쇼핑의 다음 페이지로 전환하는 버튼은 아래와 같이 셀렉할 수 있다.
for pageIdx in range(1, pageCount + 1):
try:
shopping.find_element(By.CLASS_NAME, 'pagination_next__pZuC6').click()
print("===========[{}] - [{}]".format(query, pageIdx))
except:
print("===========[{}]가 마지막 페이지입니다.".format(pageIdx))
breakpageCount는 앞선 쿼리에서 받아온 페이지 수를 담은 변수명이다.
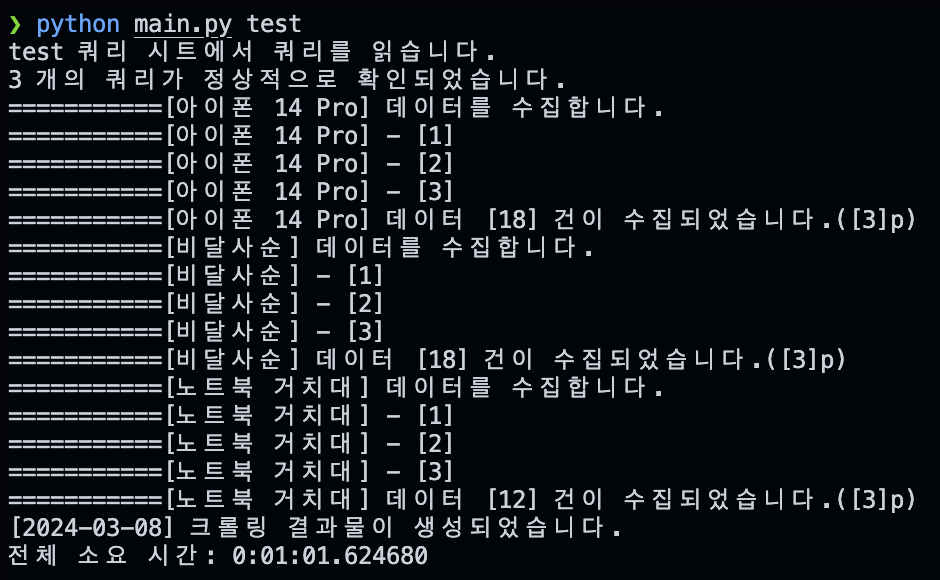
위와 같은 로그를 찍으며 수집이 정상적으로 완료된다(현재는 광고 아이템만).
# 충돌없이 결과 파일 저장
이를 위해서 두가지 방법을 고안할 수 있었다.
- 저장할 이름의 파일이 존재하면 +1 을 하여 저장하기
- 겹칠 수 없는 이름으로 저장하기
충돌없는 파일을 저장한다는 목적을 달성하기 위해 2번 방식을 사용하는 것이 간단했기 때문에 해당 방식으로 진행했다.
충돌없는 파일 명을 지정하기 위해 "현재 날짜 + 시간"의 조합을 사용했다.
from datetime import datetime
from openpyxl import Workbook
output_name = datetime.now().strftime("%y%m%d_%H%M%s")
wb = Workbook()
ws = wb.active
headers = list(crawledItems[0].keys())
for col_idx, header in enumerate(headers, start=1):
ws.cell(row=1, column=col_idx, value=header)
for row_idx, data_dict in enumerate(crawledItems, start=2):
for col_idx, header in enumerate(headers, start=1):
ws.cell(row=row_idx, column=col_idx, value=data_dict.get(header))
wb.save("results/" + output_name + ".xlsx")datetime 모듈로 실행 날짜, 시간 UNIX 방식으로 표현한 초를 사용하여 output_name을 지정하였다.
이후 openpyxl 모듈을 사용하여 엑셀 워크시트에 수집된 데이터(crawledItem)를 저장했다.
# 결과물


서치 키워드 칼럼도 하나 추가하여, 어떤 검색어를 사용했는지를 함께 저장했다.
보완할 부분은 굉장히 많지만, 네이버 크롤링 관련 포스팅을 마무리하고자 한다.
작성된 전체 코드는 아래 Repo에서 확인할 수 있다.
GitHub - Choiwonwong/crawler_navershopping: crawler for navershopping with scalability
crawler for navershopping with scalability. Contribute to Choiwonwong/crawler_navershopping development by creating an account on GitHub.
github.com
주요 파일 구조는
> main.py
- 크롤러 시작점
- 쿼리 파일 읽기, 크롬 드라이버 생성, 크롤링 요청 및 데이터 저장
> utils.py
- 단일 목적을 위해 부가적인 기능 분리
> crawling.py
- 광고 상품과 일반 상품에 대한 상세 데이터 추출 기능 분리
> queries/
- 쿼리 파일 경로
> results/
- 결과 데이터가 저장되는 경로
별로 크지 않은 볼륨이었지만, 이를 정리해가다 보니 여러가지 안좋은 습관들을 직접 확인할 수 있었던 것 같다.
코드를 한달 전에 작성하고 다시 수정해가는 과정에서 어떤 변수는 Camel Case로 작성하고 현재는 Snake Case로 작성하면서 코드의 통일성이 없었다는 생각을 했다. Java와 Python이 혼합된 느낌이련지..
또한, 셀레니움을 통해 동적인 크롤링의 장단점을 확인해볼 수 있었다. 동적인 콘텐츠의 수집이 가능하지만. 속도와 안정성을 고려하면 셀레니움보단 HTTP Request이 더 나은 선택지라고 생각할 수 있었다.
# Troble Shooting
input box 초기화
이번 프로그램에서 쿼리 스트링을 사용하지 않는 방식으로 기능을 구현하다 보니, 검색 창을 초기화해야하는 기능 구현이 필요했다.
일반적으로는 쿼리에 검색어를 집어넣는 방식으로 검색 결과 페이지에 접근하지만, 인풋 박스를 직접 수정하며 새로운 값을 입력하고 싶다면 아래의 방을 사용해야한다.
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
search = shopping.find_element(By.XPATH, "/html/body/div/div/div[1]/div[2]/div/div[2]/div/div[2]/form/div[1]/div/input") # XPATH
search.send_keys(Keys.COMMAND, 'a')
search.send_keys(Keys.DELETE)키보드로 전체 선택 + 삭제 키를 입력하는 로직이다.
이는 OS 환경에 따라 조금 다를 듯 한데, Mac OS 환경에서 개발되었어서 'Keys.COMMAND, a'을 통해 정상적으로 모두 선택이 수행되었다.
윈도우의 경우 위 코드가 동작하지 않으면 안되면, 'COMMAND'를 'CONTROL'로 바꿔 실행하면 되지 않을까 생각된다.
# 페이지 전환 간 명시적 Sleep
페이지를 전환하는 로직을 추가한 후 테스트를 진행했을 때, 첫번째 페이지에선 정상적으로 동작하는데 페이지가 전환되자마자 Element를 찾지 못했다는 경고창을 맞이할 수 있었다.

이 문제는 페이지가 전환된 후 로딩이 완료될때까지의 시간이 부족했기 때문이었음을 확인할 수 있었다.
페이지 전환 이후 2초의 명시적인 sleep을 통하여 문제를 해결했다.
쇼핑 페이지 모달 처리
한달정도 이후 다시 테스트를 하다 보니 네이버 쇼핑 접속 시에 모달이 추가되었음을 알 수 있었다.

이걸 닫아주지 않으면 쇼핑 검색 버튼 클릭을 할 수 없어서, 닫아주는 로직을 추가했다.
이런 예외가 얼마든지 발생할 수 있기 때문에, 셀레니움은 정말 특정한 사이트에서만 사용이 가능할 것 같다는 생각과 동적으로 컨텐츠를 수집할 수 있다는 장점에서 나오는 단점을 확인할 수 있었다.
from selenium.webdriver.common.by import By
Modal_SELECTOR = "div._buttonArea_button_area_2o-U6 > button._buttonArea_button_1jZae._buttonArea_close_34bcm"
if driver.find_element(By.CSS_SELECTOR, Modal_SELECTOR):
driver.find_element(By.CSS_SELECTOR, Modal_SELECTOR.click()
만약 네이버 쇼핑에서 다른 클래스 명을 가진 모달을 추가할 경우 추가적인 작업을 진행해야한다.
'Tech > Etc' 카테고리의 다른 글
| Windows에서 git bash에서 conda 명령어 사용하기 - bash_profile (0) | 2025.05.07 |
|---|---|
| CSS Selector & XPath 개념 및 사용법 (7) | 2024.04.12 |
| 네이버 쇼핑 검색 과정 자동화(크롤링) with Selenuim - 1 (47) | 2024.03.03 |