


# 목적
RDB 테이블에 담긴 데이터 중 특정 칼럼의 중복 제거 후 전체 칼럼을 조회하는 방법을 공유하고자 한다.
엑셀로는 간단하게 "중복된 항목 제거"라는 기능을 사용할 수 있는데, 데이터가 너무 많아 엑셀에서 편집이 불가능한 경우에는 SQL에서 중복 제거를 수행해야한다.

SQL 이를 수행하려고 하니 DISTINCT로는 할 수 없었고, 조금 복잡한 로직을 타야했다.
DISTINCT로 해결하는 방법은 이번 포스팅에 작성되어있지 않다.
해당 방식에 대해서 아래의 포스팅을 참고했다.
[ SQL ] 중복 제거하고 조회하기
중복을 제거하고 조회(SELETE)하는 방법은 다양하다. 그 중에서 알고 있는 3가지 방법에 대해서 적어볼려고 한다. 사용한 DBMS : ORACLE SQL 클라이언트 : DBeaver 빠른 이해를 위해 EMPLOYEE_TEST 테이블의 중
jerrys-ai-lab.tistory.com
실습에 사용한 사이트는 아래와 같다. 데스크탑에 DB 세팅이 안되어있어서 예시를 보여주기 위해서만 사용했다.
SQL Test
Free Online SQL Test Tool
sqltest.net
사용할 RDBMS는 MySQL 5.6이다.
# 요구 사항
위의 테이블에서 John Doe라는 사람의 데이터는 중복되어 저장됨을 확인할 수 있다.
만약 email 칼럼을 기준으로 중복 데이터만을 제거한 전체 테이블을 조회하고 싶다면, DISTINCT 만으론 간단하게 해결하기 어렵다.
`SELECT DISTINCT *`을 사용하더라도 Unique한 다른 칼럼(id, reg_date)이 존재하기 때문에 중복 데이터가 제거되지 않는다.
DISTINCT를 통해 email의 중복을 제거하더라도 중복을 제거하는데 조회할 칼럼을 명시해야하기 때문에 전체 칼럼을 조회하는 것 제한된다.
해당 테이블을 기준으로 Join 연산을 수행해도 중복된 데이터를 제외한 전체 칼럼을 조회하긴 쉽지 않다.
해결 방안 - ROW_NUMBER(), PARTITION BY
이를 해결하기 위한 방법을 요약하면,
중복된 데이터가 존재하는 칼럼을 그룹핑하여 고유한 번호(ROW NUMBER)를 찍고,
첫번째 고유한 번호를 선택하여 중복을 제거하는 방법
이를 일반적으로 작성한 코드는 다음과 같다.
SELECT A.*
FROM (
SELECT *, ROW_NUMBER() OVER(PARTITION BY 중복을 제거할 수 있는 기준 칼럼 ORDER BY {고유번호를 찍을 기준 칼럼}) AS {행별 고유번호}
FROM {테이블_명}
) AS A
WHERE {행별_고유번호} = 1
;이를 이해하기 위해선 ROW_NUMBER() 함수와 OVER 절의 PARTITION BY를 이해하면 된다.
# ROW_NUMBER()
ROW_NUMBER는 OVER 절과 함께 사용되는 SQL 함수로 OVER 절 내에 정의되는 ORDER BY 구문에 따라 행별 고유번호를 찍어준다.
SELECT *, ROW_NUMBER() OVER(ORDER BY id) AS RN
FROM mysql_test_aPARTITION 절이 없는 위의 코드를 실행하면 RN 칼럼의 값은 ID와 동일함을 확인할 수 있다.
# PARTITION BY
PARTITION BY는 GROUP BY와 유사한 기능을 하지만, 특정 칼럼에 대한 집계를 전체 칼럼에 대해 적용해준다.
GROUP BY를 사용하면 그룹화된 칼럼에 대해서만 집계 함수를 적용할 수 있다는 것에 차이가 존재한다.
동일한 목적을 달성하기 위해 두 방식을 직접적으로 비교하면 다음과 같다.
-- Group by로 이메일 별 개수 반환
SELECT email, COUNT(email) as count
FROM mysql_test_a
GROUP BY email
;-- Partition by로 이메일 별 개수 반환
SELECT *, count(*) over(PARTITION BY email) as count
FROM mysql_test_a
ORDER BY id
;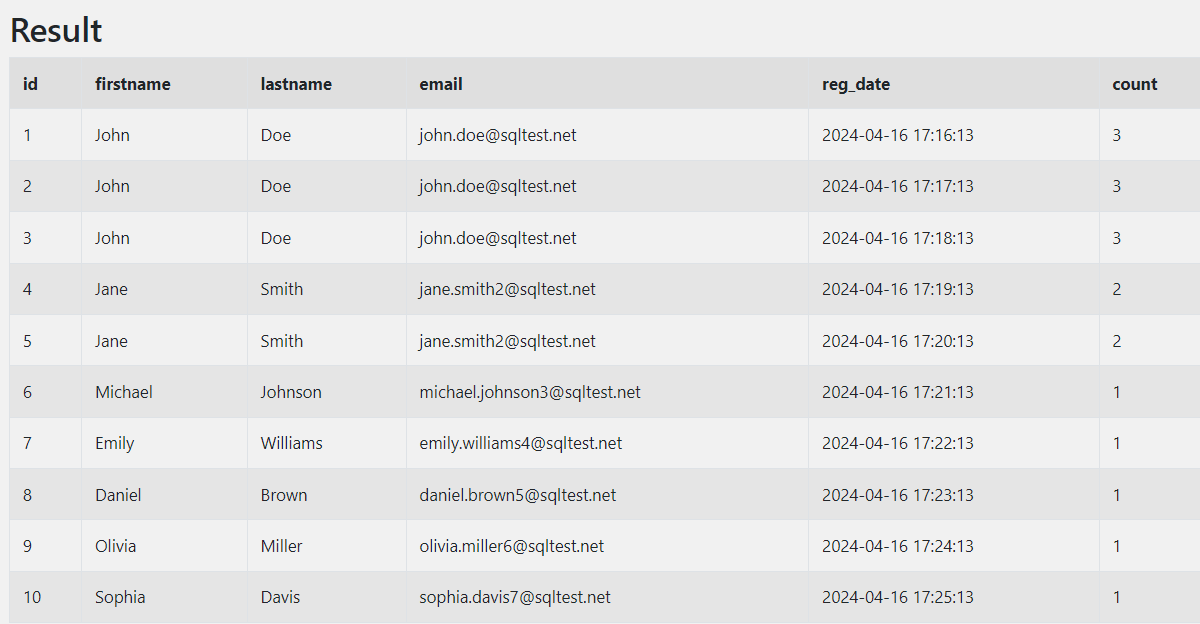
GROUP BY와 달리 집계 함수와 OVER(PARTITION BY)를 사용하여, 전체 칼럼과 데이터에 대해 집계 결과를 확인할 수 있음을 알 수 있다.
# SubQuery 확인
앞서 ROW_NUMBER() OVER(PARTITION BY) 문을 사용하여 만든 서브쿼리 테이블을 확인해보면 아래와 같다.
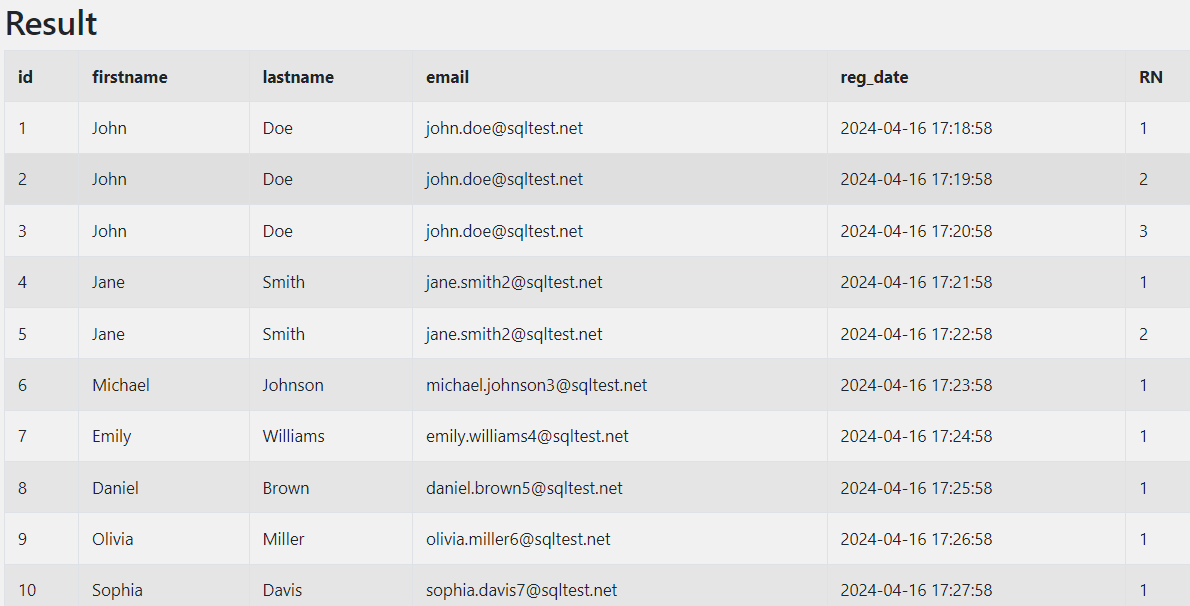
즉, email을 기준으로 그룹화를 하고 id 값에 대해 정렬된 행 번호를 찍게 된다.
# 결과 확인
중복을 제거하기 위해선 RN=1인 값만 선택하면 된다.
SELECT A.*
FROM (
SELECT *, ROW_NUMBER() OVER(PARTITION BY email ORDER BY id) AS RN
FROM mysql_test_a
) AS A
WHERE 1=1
AND RN = 1;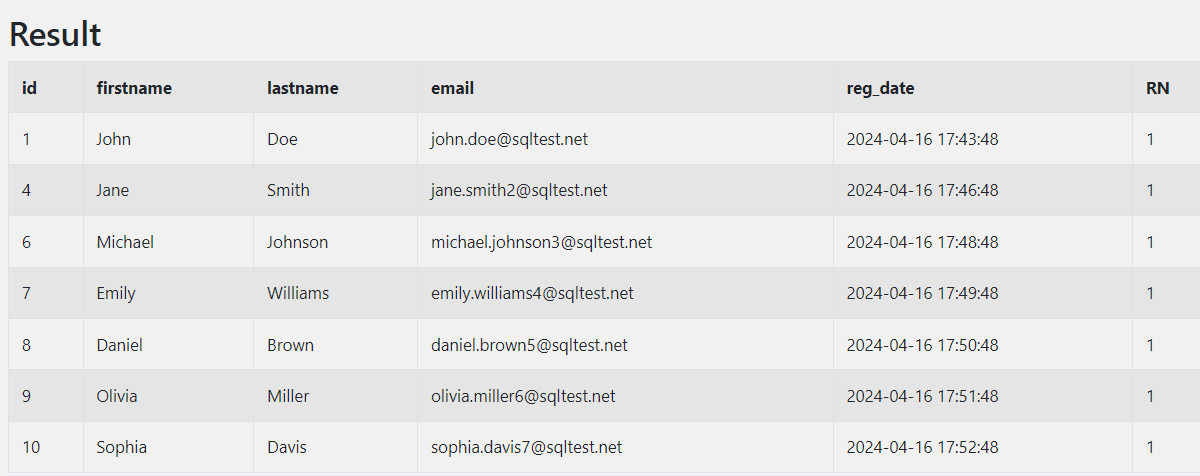
이제 최초에 원했던 email을 기준으로 중복된 데이터를 제거한 전체 데이터를 확인할 수 있다.
SQL에선 특정 칼럼을 제외하여 조회하는 기능은 없기 때문에, RN 칼럼을 제외하고 싶으면 SELECT 부분에 RN을 제외한 나머지 칼럼을 지정해주면 된다.
엑셀의 '중복된 데이터 제거' 기능을 SQL로 사용하기 위해선 조금 로직이 필요하다.
데이터가 RDB에 저장되어 있고 중복된 데이터가 있지만 유니크한 다른 칼럼이 존재하는 경우, 데이터가 너무 많아 엑셀에서 뽑아서 수정하기 어렵다면 이 방식으로 특정 칼럼의 중복을 제거할 수 있다.
'Dev > Etc' 카테고리의 다른 글
| Hive Table 복구 회고 with Airflow catchup 설정 (0) | 2024.07.27 |
|---|